【Java并发编程的艺术3】Java内存模型(中)
前言
这篇文章主要介绍重排序与顺序一致性内存模型
重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分为下列3种类型,如下表所示:
| 名称 | 代码示例 | 说明 |
|---|---|---|
| 写后读 | a = 1; b = a; |
写一个变量之后,再读这个位置 |
| 写后写 | a = 1; a = 2; |
写一个变量之后,再写这个变量 |
| 读后写 | a = b; b = 1; |
读一个变量之后,再写这个变量 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。
编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial语义
不管怎么进行重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可以被编译器和处理器重排序。
1 | double pi = 3.14; //A |
上面3个操作的数据依赖关系如下图所示
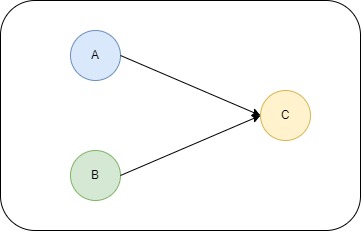
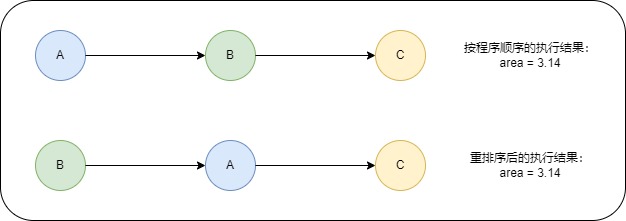
A与C之间存在数据依赖关系,B与C之间存在数据依赖关系,因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序,下图是该程序的两种执行顺序
重排序对多线程的影响
现在看一下重排序是否会改变多线程程序的执行结果,示例代码如下:
1 | public class RecordExample { |
flag变量是个标记,用来标识变量a是否已经被写入。这里假设有两个线程A和B,A首先执行writer()方法,随后B线程接着执行reader()方法。线程B执行操作4时,能否看到线程A在操作1对共享变量a的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,操作3和操作4也没有数据依赖关系,编译器和处理器分别可以对这两组操作进行重排序,下图展示了操作1和操作2重排序时,可能会产生什么效果。
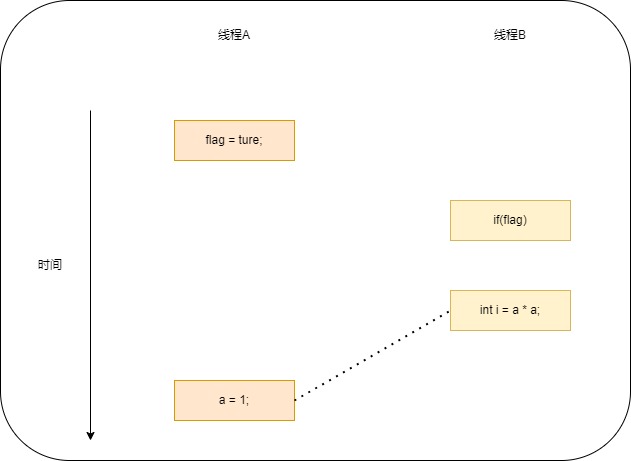
程序执行时,线程A首先写标记变量flag,随后线程B读这个变量。由于条件判断为真,线程B将读取变量a。此时变量a还没有被线程A写入,这里多线程程序的语义被重排序破坏了。
顺序一致性
顺序一致性内存模型是一个理论参考模型,在设计的时候,处理器的内存模型和编程语言的内存模型都会以顺序一致性内存模型作为参照。
数据竞争与顺序一致性
当程序未正确同步时,就可能会存在数据竞争。Java内存模型规范对数据竞争的定义如下:
- 在一个线程中写入一个变量
- 在另一个线程中读同一个变量
- 而且写和读没有通过同步来排序
顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特性。
- 一个线程中的所有操作必须按照程序的顺序来执行。
- (不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。
顺序一致性内存模型为程序员提供的视图如下图所示:
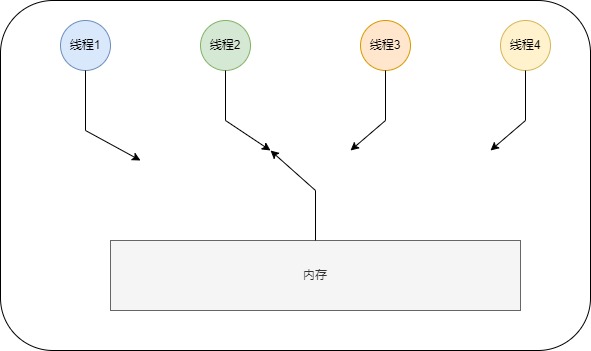
在概念上,顺序一致性模型有一个单一的全局内存,这个内存通过一个左右摆动的开关可以连接到任意一个线程,同时每一个线程必须按照程序的顺序来执行内存读/写操作。在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存读/写操作串行化(即在顺序一致性模型中,所有操作之间具有全序关系)。
下面通过两个示意图来对顺序一致性模型的特性做进一步的说明。
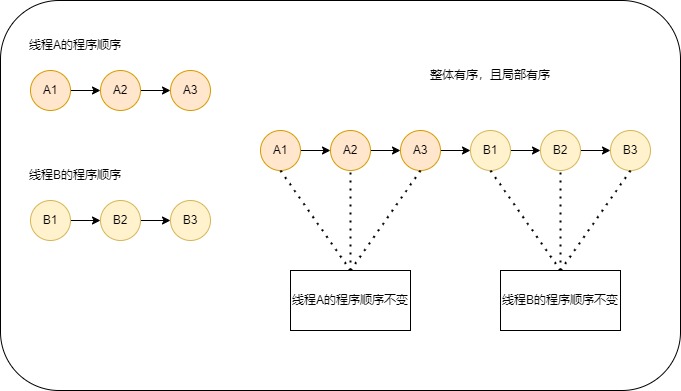
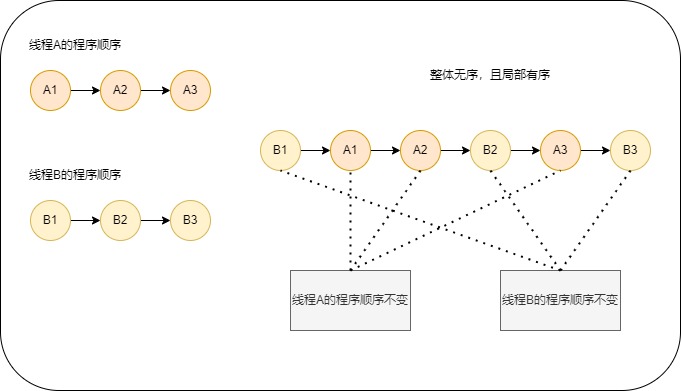
假设有两个线程A和B并发执行。其中A线程有3个操作,它们在程序中的顺序是:A1->A2->A3。B线程也有3个操作,它们在程序中的顺序是:B1->B2->B3。
假设这两个线程使用监视器锁来正确同步:A线程的3个操作执行后释放监视器锁,随后B线程获取同一个监视器锁。那么程序在顺序一致性模型中的执行效果如下图所示:
在假设这两个线程没有做同步,下面是这个未同步在顺序一致性模型中的执行示意图,如下图所示;
同步程序的顺序一致性效果
示例如下:
1 | public class SynchronizedExample { |
在上面的代码示例中,假设线程A执行writer()后,线程B执行reader()方法。这是一个正确同步的多线程程序。
顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在JMM中,临界区中段代码可以重排序(但JMM不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义。)虽然线程A可能在临界区内做了重排序,但由于监视器互斥执行的特性,这里的线程B根本无法“观察”到线程A在临界区内的重排序,这种重排序既提高了执行效率,又没有改变程序的执行结果。
未同步程序的执行特性
对于未同步或未正确同步的多线程程序,JMM只提供最小安全性,线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,Null,False),JMM保证线程读操作读取到的值不会无中生有地冒出来。
JMM不保证未同步程序的执行效果与该程序在顺序一致性模型中的执行结果一致。
未同步程序在JMM中的执行时,整体上是无序的,其执行结果无法预知。未同步程序在两个模型中的执行特性有如下几个差异:
- 顺序一致性模型保证单线程内的操作会按程序的顺序执行,而JMM不保证单线程内的操作会按程序的顺序执行
- 顺序一致性模型保证所有线程只能看到一致地操作执行顺序,而JMM不保证所有线程能看到一致地操作执行顺序。
- JMM不保证对64位的long型和double型变量的写操作鱼油原子性,而顺序一致性保证对所有的内存读/写操作都具有原子性。